NCEA Compatibility
Module: as91902 Use complex techniques to develop a database
Requirements: designing the structure of the data
Go to top
Module: as91902 Use complex techniques to develop a database
Requirements: designing the structure of the data
Go to topOn completion of this section you will know how to design the data structure of a database through the process of normalisation
Go to top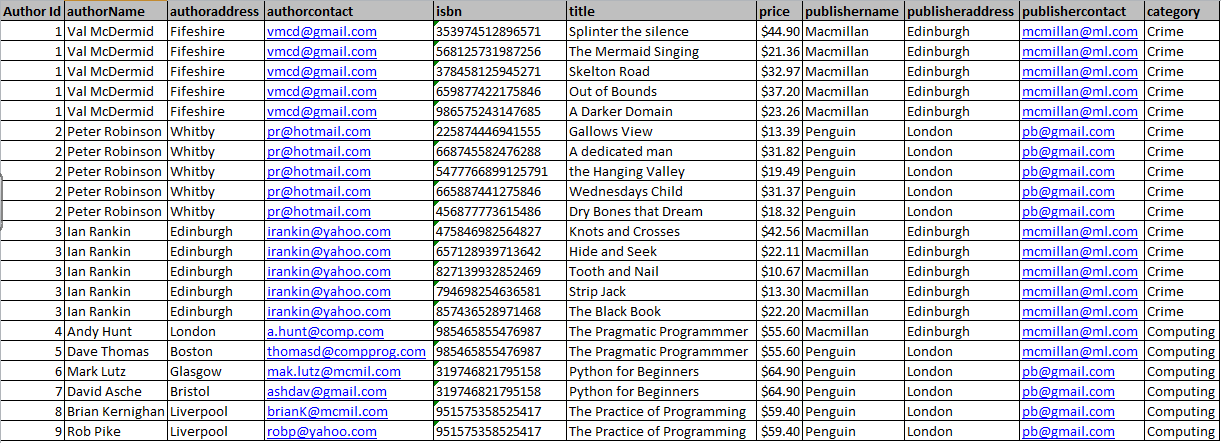
Fig 1 above shows a flat file containing details of authors, their books and the publishers who have published those books. The type of data storage shown above is referred to as flat file storage. What this means is that all of the data relating to authors, books and publishers is stored in a single file.
For the beginner there is a small number of advantages to this system:
On the other hand, if the number of records gets larger, problems will begin to occur.
We notice that for each book they write the author’s name appears with each book. As well as the name of the author, their address and contact details also appear. (Here the contact details is limited to an email address, but in a real live system they would extend to phone#, cellphone#, fax number, as well as phone number for office and for their agent.) This is a lot of data to keep repeating, especially for an author with a lot of books to their credit. The first problem we notice is that extra storage space is taken up.
Updating can be difficult because if an author changes their address or their contact details then the same details will have to be updated for each book that the author has written. So if an author has written 20 books the same details about the author will have to be repeated 20 times.
Not only is this form of updating very time consuming but it also is tedious and frustrating and consequently is error prone. This could lead to the author having erroneous contact details for some of their book. This problem could be compounded by the fact that during the updating process some author records may be skipped, thus leaving them with their previous, and therefore, erroneous contact details.
What we have said about authors can also be applied to publishers, since each publisher’s details are repeated for each book that they have published and therefore the same problems are associated with updating them.
In order to overcome the issues of excessive storage and inefficient updating we turn to a discipline called Normalisation. This is a technique for breaking the large block of data into smaller and more manageable groupings and cross-referring different groups to each other through what is referred to as Relationships.
Looking at the data in Fig 1 we see that there are three entities in the data: authors, books and publishers. Examining those entities we see that books are written by authors and therefore we have an author-book relationship. Similarly, publishers publish books: giving us a publisher-book relationship.
Go to topOf the two relationships in our sample data, we shall first look at the publisher-book relationship since it is the simplest and easiest to resolve.
A publisher publishes many books while each book is published by only one publisher. For this reason, we refer to the publisher-book relationship as one-to-many, i.e. one publisher for many books.
We now use this relationship to perform the first step of normalisation
The first step here is to remove the publisher details to another table. Once you do this you can remove all of the repetitions and in the case of our example you will end up with only two records in your table, as shown in Fig 2 below.

Now you should be able to see one of the advantages of normalisation. Instead of the rows of repetitions in Fig 1 of the publishers’ details, you now have two rows – one for each publisher.
The new table, as it is shown here, is of no use to us, however, since it has been separated from the books and there is no way of referring it back to the other table.
This problem is solved, however, by adding an Id number to each publisher, and adding the same id to the books table. This is shown below in Fig 3.
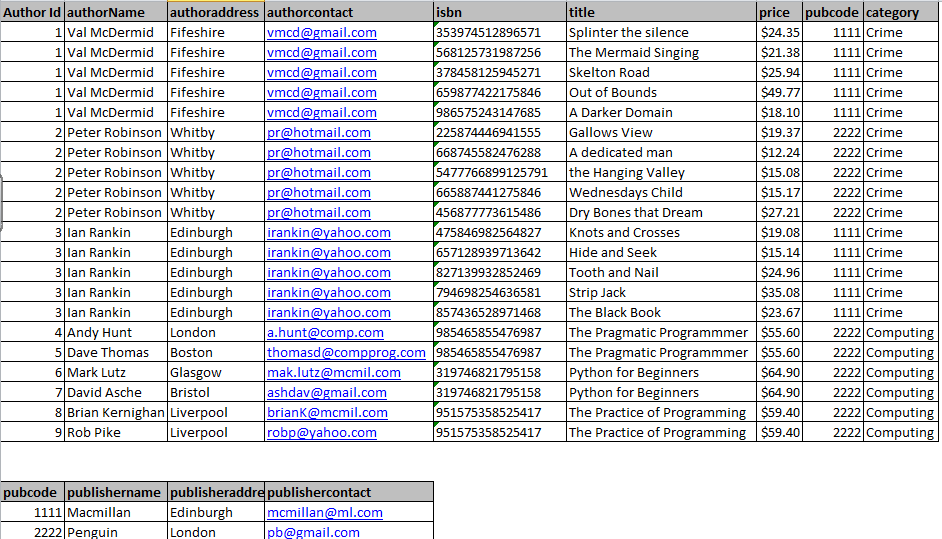
Using the publisherCode fields of both tables for cross referencing purposes we can now match out publishers and books. Checking the books ‘Skelton road’ and ‘The Hanging Valley’ we see that the former has a publisher code of 1111, which, when we check the publisher table we see is Macmillan, while the latter has a publisher code of 2222, which tells us that it was published by Penguin.
Go to topEstablishing the relationship between the book and publisher tables had been reasonably simple since any book is published by only one publisher. On the other hand the relationship between author and book is more complex since an author can write many books, while a book can be written by more than one author. This book-author relationship is referred to as a many-to-many relationship
To solve this relationship we create an extra table into which we copy the keys of the author and publisher entities only – ensuring that the author codes correctly match up with the isbn numbers. Finally we remove all of the author details to their own table. This table will now reduce considerably is size since we can remove all of the repetitions of the same author.
The resulting normalized data is shown in Fig 4 below.
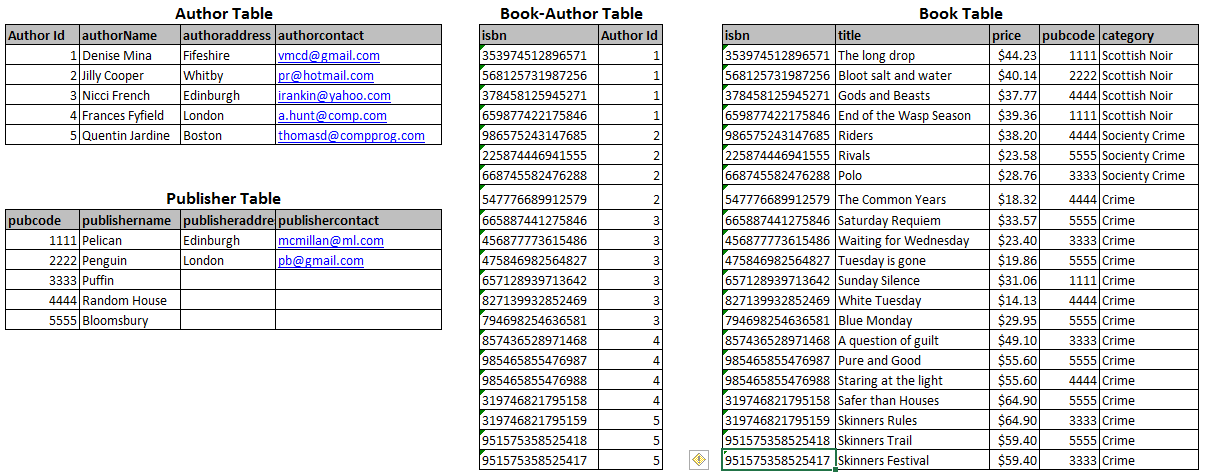
The table below shows the key fields for each of our tables.
| Author | Author Id |
| Publisher | Pubcode |
| Book | isbn |
| Book-Author | isbn, Author Id |
As stated in an earlier chapter, a key field identifies a unique item the table and for this reason all databases prohibit repetition of values in the key field. When it comes to cross-referring between related tables, however, key fields really come into their own.
Let us first look at the publisher and book tables. If we wish to know which books are published by Macmillan we first look at the key for Macmillan, which in the pubcode field. This turns out to be 1111. Next we search the pubcode field of the book table for this value. We find it in rows 1-5 and 11-16. This means that Macmillan publishes the books listed in those rows.
To summarise the above paragraph we used the pubcode field in the Publisher table to cross-refer to the pubcode field in the Book table. Now, to use some formal database jargon, regarding the publisher-book relationship we refer to the pubcode field in the Publisher table as the main key of the relationship while we refer to the pubcode field in the Book table as the foreign key.
To look at how this relationship actually works we shall look at a simple search of the Publisher and Book tables. If were wanted to find out who published the book Tooth and Nail we take the following steps:
Now we shall look at a search in the opposite direction. Here we shall try to find out what books are published by Penguin. Again this is a two stage process:
As stated earlier, due to the fact that authors can write many books and that books can be written by more than one author the author-book relationship is many-to-many. Databases cannot resolve many-to-many relationships and therefore that relationship is broken up into two one-to-many relationships.
The first of those relationships is between the Author and Book-Author tables. Here the Author Id in the Author table forms the main key of the relationship while the AuthorId field of the Book-Author table forms the foreign key.
Similarly the isbn field of the Book Table forms the main key of the second relationship while the isbn field of the Book-Author table forms the foreign key. The Book-Author table, thus, acts as an intermediary between the Author and Book tables. For this reason, matching books with their authors take more steps than matching books with their publishers.
As an example we shall try to find who the author of The Hanging Valley is. The steps are:
To go in the opposite direction we shall try to find out all of the books published by Val McDermid. Again the steps are:
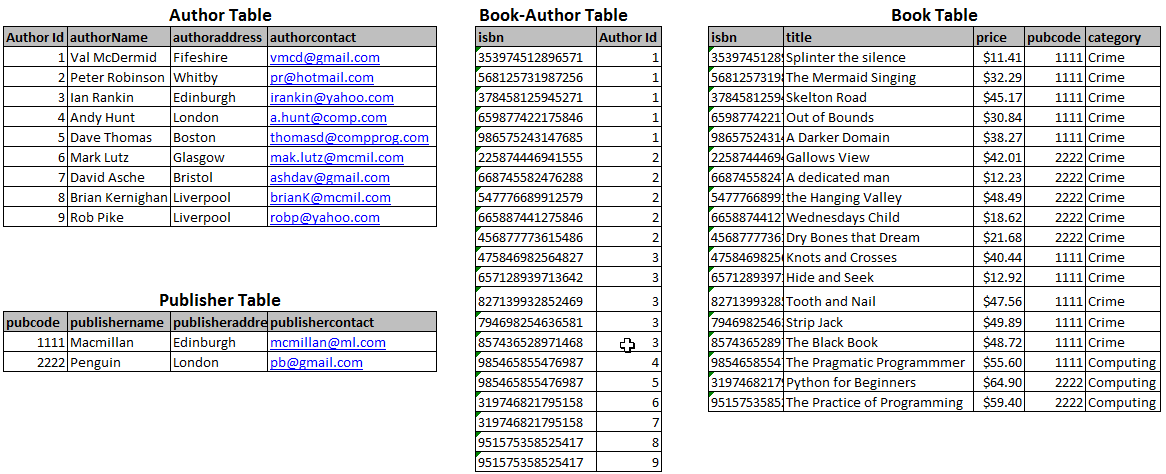
Try the following exercises:
Above we used a very ad hoc method for normalising our data. Here we look at a more formal way of doing it. Normalisation has three levels which are:
So what does this all mean? To answer that let us examine the following data.
(AuthorId, authorName, authorAddress, authorContact, isbn, title, price, publisherId, publisherName, publisherAddress, publisherContact, category)
Firstly what do we mean by a repeating group and then what do we mean by removing it?
In the data list above the field AuthorId is the key field – identified by the fact that it is underlined. The next three data items clearly refer to the name, address and contact details of an author. The rest of the data items refer to a book. Since an author can write any number of books the items price, publisherId, publisherName, publisherAddress, publisherContact, category is regarded as a repeating group and for this reason must be removed. Once this is done our data will look as follows:
AUTHOR (AuthorId, authorName, authorAddress, authorContact)
AUTHOR-BOOK (AuthorId, isbn, title, price, publisherId, publisherName, publisherAddress, publisherContact, category)
As stated in our first rule, we have copied the key field of the Author group into the Book group. Also since an author can write many books and a book can be written by any number of authors we have a many-to-many relationship here and so both the isbn and the AuthorId fields must be part of the key field in what is technically known as a composite key.
By now our first stage of normalisation is complete.
The second stage is to remove all items not directly related to all parts of the composite key. Since the AUTHOR group has a single key, this stage does not apply to it. The AUTHOR-BOOK group, however, has a composite key and thus we shall examine it.
The title item relates directly to the isbn and only indirectly relates to the AuthorId. The same applies to all of the other items of the group. Once we remove isbn and all the items that follow it we will have the arrangement shown below.
AUTHOR-BOOK (AuthorId, isbn)
BOOK (isbn, title, price, publisherId, publisherName, publisherAddress, publisherContact, category)
We have now completed the second stage and only the third stage remains, which is to remove all items not directly related to the key field. Clearly this applies only to the AUTHOR and BOOK groups.
In the AUTHOR group the last three items clearly are directly related to the key field and thus we have no need to change that group.
In the BOOK group the items title, price and publisherId relate directly to the isbn field, while publisherName, publisherAddress and publisherContact are directly related to the publisherId field and only indirectly related to the isbn field.
The final item, category, is directly related to the isbn field.
From this we deduce that publisherName, publisherAddress, publisherContact will be removed from that group and a copy of publisherId will be added to them. They will form a new group as shown below named PUBLISHER.
PUBLISHER (publisherId, publisherName, publisherAddress, publisherContact)
The reduced BOOK group will be
BOOK (isbn, title, price, publisherId, category)
With the three normalisation rules applied, our group arrangement will now be as shown below. We have created the design for our database tables.
AUTHOR (AuthorId, authorName, authorAddress, authorContact)
AUTHOR-BOOK (AuthorId, isbn)
BOOK (isbn, title, price, publisherId, category)
PUBLISHER (publisherId, publisherName, publisherAddress, publisherContact)
Go to top
Normalisation is a technique for breaking down a large block of data into smaller and more manageable groupings. The process of normalisation is carried out in three stages:
Once the process is complete the data will be in a form that is ready for use in a database.
Go to top